[ICML 2026] Rule2DRC
Rule2DRC: Benchmarking LLM Agents for DRC Script Synthesis with Execution-Guided Test Generation
Rule2DRC benchmarks LLM agents that turn natural-language chip design rules into executable DRC scripts, graded by running them on test layouts.
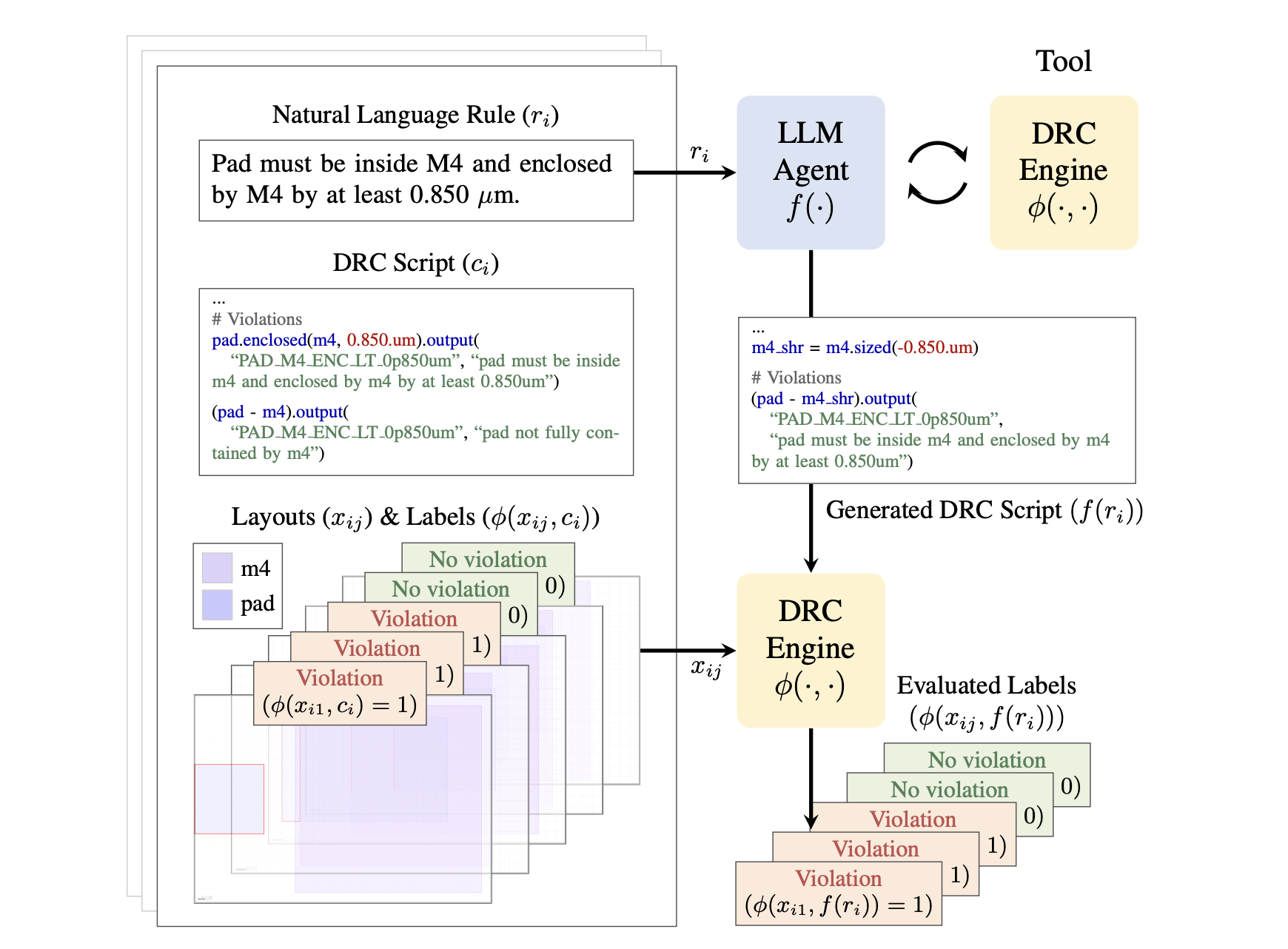
Overview
Before a chip layout can be manufactured, it must satisfy thousands of geometric design rules. Design Rule Checking (DRC) enforces them by running executable scripts on the layout and reporting violations. Writing a correct script for each natural-language rule is labor-intensive, demands specialized expertise, and must be repeated for every process node. This makes DRC script synthesis a natural target for LLM agents, yet progress has been hard to measure.
Rule2DRC is a large, fully open benchmark for this task, with 1,000 rule-to-script tasks and 13,921 evaluation layouts. An agent sees only the rule and must produce a script, and we grade it by execution rather than code similarity.
We also introduce SplitTester, an execution-guided test generation agent that improves Best-of-N selection by generating test layouts that separate candidate scripts.
The Rule2DRC Benchmark
An agent receives only the rule and must produce a short script in a domain-specific language, run by the open-source KLayout engine on layouts in the GDSII format. A rule such as "Pad must be inside M4 and enclosed by M4 by at least 0.850 µm" maps to a script like the one below.
pad.enclosed(m4, 0.850.um)
.output("PAD_M4_ENC", "pad must be enclosed by m4 by at least 0.850um")
(pad - m4).output("PAD_M4_ENC", "pad not fully contained by m4")Prior evaluations of DRC script synthesis share a few limitations. Their test sets are small, often under 200 rule-and-script pairs. They compare scripts by surface-level code similarity, which is unreliable because the same rule can be written in many syntactically different but functionally equivalent ways. And they are rarely released, since the underlying rules and layouts are proprietary. Execution feedback is also underused, as some methods never run the DRC engine and others require evaluation layouts with ground-truth labels as agent input, the very expert effort we aim to remove.

How Rule2DRC compares with prior DRC benchmarks across scale, evaluation, input requirements, and openness.
Rule2DRC is designed to remove each of these limitations. It is far larger than prior test sets, with 1,000 rule-to-script tasks and 13,921 evaluation layouts. It grades by execution instead of code similarity, marking a task solved only when the generated script and a ground-truth script agree on every evaluation layout. It is fully open source, including the rules, the layouts, and the evaluation pipeline. And it keeps the evaluation layouts hidden from the agent, so the agent cannot rely on labeled examples and must generate its own tests.
The 1,000 tasks span three groups.
- SkyWater-derived (310). Extracted from the public SkyWater130 PDK, with threshold and topological corner cases such as partial overlap and containment.
- Synthetic multi-constraint (490). Multi-layer rules with chained geometric operations in the style of advanced nodes, model-drafted then hand-reviewed.
- Syntax coverage (200). Rules exercising rarely used grammar, bringing the benchmark to 184 unique DRC methods overall.

Example rule-to-script tasks, each paired with its ground-truth DRC script.
Documentation in Context
The KLayout DRC language is niche, so we crawled the official documentation into a single 60K-token document and include it in the prompt. On GPT-OSS-120B this raises pass@1 by over 20 points and pass@20 by over 40 points, a larger effect than the gap between any two selection methods. For domain-specific languages, in-context documentation is a prerequisite rather than an optimization, so all remaining experiments include the document.
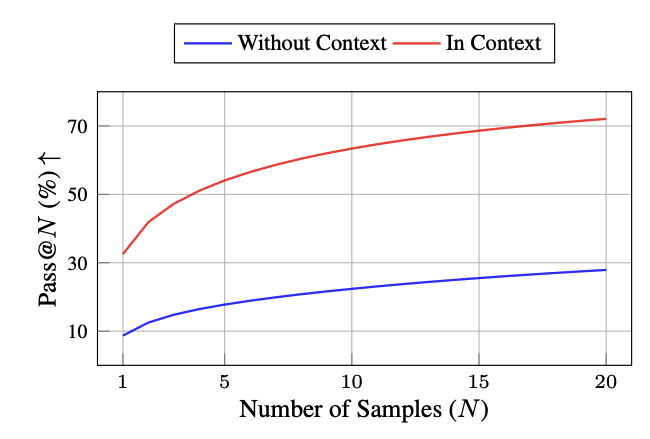
Putting the KLayout API documentation in context lifts pass@1 by over 20 points and pass@20 by over 40 points (GPT-OSS-120B).
SplitTester
The DRC engine gives the agent an executable environment, so a natural recipe is Best-of-N. We sample N candidate scripts, generate test layouts with expected outcomes, and select the candidate that scores best. The challenge is selection. Models rarely produce the corner cases that separate a correct script from a nearly correct one, so many candidates behave identically under weak tests.
SplitTester targets those indistinguishable groups directly. It clusters candidates by execution behavior, picks the cluster with the largest product of score and size, where correct and nearly correct scripts are most likely still mixed, and prompts the LLM to generate a test that splits that cluster. This repeats until the test budget runs out. A judge LLM then selects among the top candidates using the tests on which they disagree, inspecting concrete behaviors rather than trusting noisy self-generated labels.
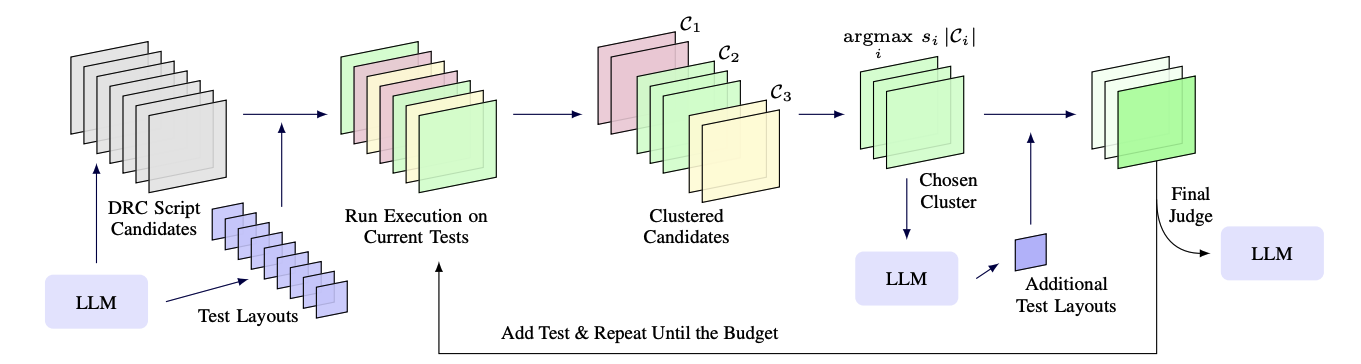
SplitTester aims new tests at the clusters current tests cannot tell apart, then selects with a judge.
Results
We evaluate Qwen3-30B-A3B-Instruct, GPT-OSS-20B, and GPT-OSS-120B under Best-of-N selection with a fixed budget of 16 test layouts. SplitTester achieves the best success rate in every setting. For example, it reaches 44.4% versus 41.1% on GPT-OSS-20B with 20 candidates, and 63.8% versus 62.7% on GPT-OSS-120B, where Oracle@20 is 72.1%. Error rates drop as well.
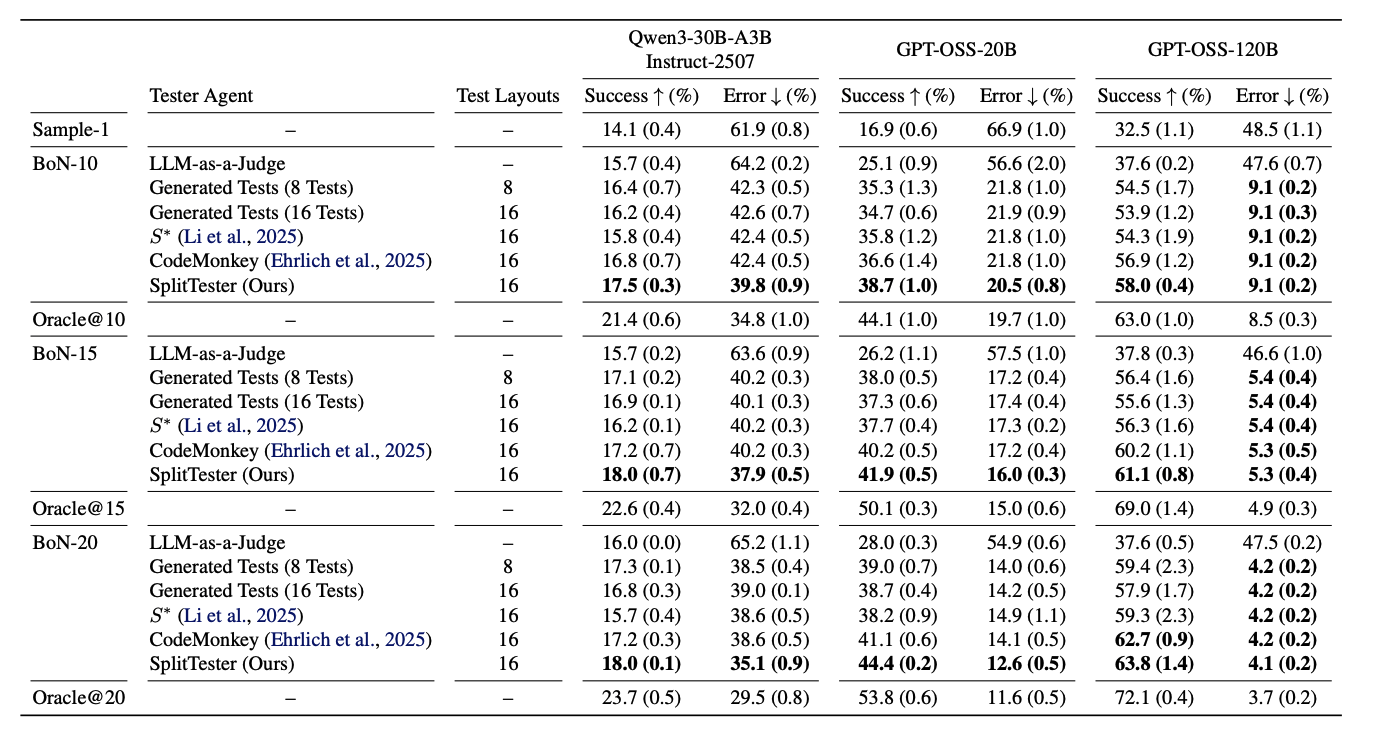
Success and error rates under Best-of-N selection. SplitTester achieves the best success rate in every setting.
SplitTester also lies on the runtime Pareto frontier for all three models, so its higher success rate does not come from spending more compute. The gains also hold with half the test budget and across all rule categories.
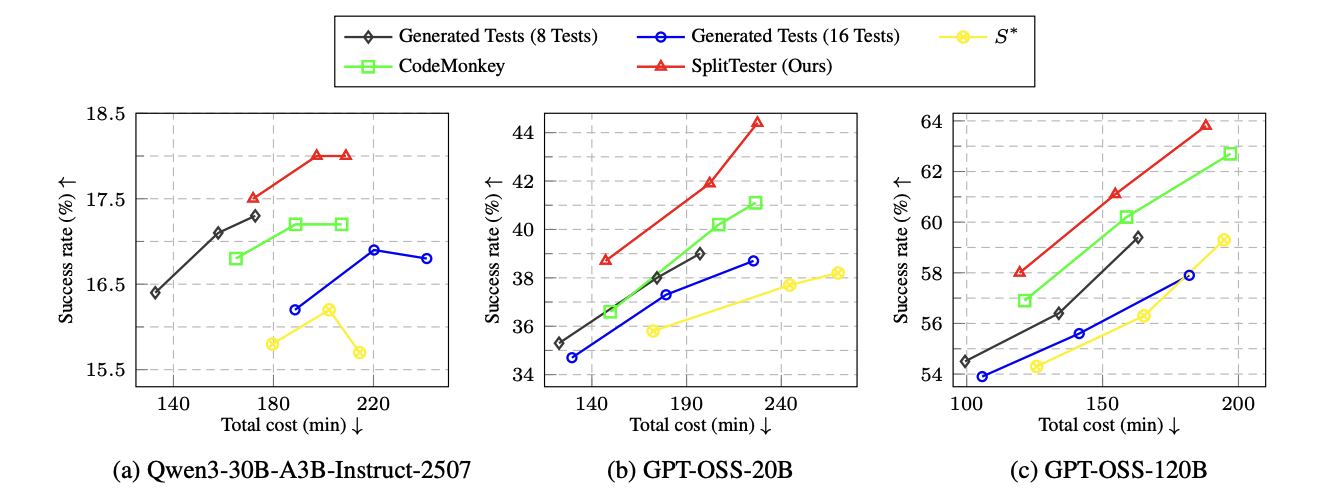
Runtime versus success rate. SplitTester lies on the Pareto frontier for all three models.
BibTeX
@InProceedings{kim2026rule2drc,
title = {Rule2DRC: Benchmarking LLM Agents for DRC Script Synthesis with Execution-Guided Test Generation},
author = {Kim, Jinuk and Byun, Junsoo and Hwang, Donghwi and Park, Seong-Jin and Song, Hyun Oh},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning},
year = {2026},
volume = {306},
series = {Proceedings of Machine Learning Research},
publisher = {PMLR}
}